
The world of data analysis is vast and complex, with numerous techniques and tools available to help uncover hidden patterns and insights. Among these techniques, cluster analysis stands out as a powerful method for identifying groups within a dataset. One of the most popular and widely used clustering algorithms is K-Means, and when combined with the versatility of Microsoft Excel, it becomes a formidable tool for data analysis. In this article, we will delve into the world of Excel K-Means cluster analysis, exploring its importance, benefits, and providing a step-by-step guide on how to master it.
Understanding the Importance of Cluster Analysis
Before diving into the specifics of K-Means in Excel, it's essential to understand why cluster analysis is so valuable. In a nutshell, cluster analysis is a method of grouping similar objects or data points into clusters, based on their characteristics. This technique allows analysts to identify patterns, relationships, and structures within a dataset that might not be immediately apparent. Cluster analysis has numerous applications across various fields, including marketing, finance, biology, and more.
What is K-Means Cluster Analysis?
K-Means is a specific type of cluster analysis algorithm that partitions the data into K clusters based on their similarities. The algorithm works by initially randomly assigning each data point to a cluster, and then iteratively updating the cluster assignments based on the mean distance of the points from the cluster center. This process continues until the cluster assignments stabilize, resulting in K distinct clusters.
Benefits of Using K-Means in Excel
While there are many software packages and programming languages that support K-Means clustering, using Excel offers several advantages:
- Familiarity: For many analysts, Excel is a familiar and comfortable environment, making it easier to learn and implement K-Means clustering.
- Flexibility: Excel's flexibility allows users to easily manipulate and experiment with different datasets, algorithms, and parameters.
- Visualization: Excel's robust visualization capabilities make it simple to interpret and communicate the results of the cluster analysis.
Mastering Excel K-Means Cluster Analysis: A Step-by-Step Guide
Now that we've covered the importance and benefits of using K-Means in Excel, let's dive into the step-by-step process of mastering this technique.
Step 1: Prepare Your Data
Before applying the K-Means algorithm, it's crucial to prepare your data. This involves:
- Ensuring the data is clean and free of errors
- Scaling the data, if necessary, to prevent features with large ranges from dominating the clustering process
- Selecting the relevant features or variables to include in the analysis

Step 2: Choose the Optimal Number of Clusters (K)
Determining the optimal number of clusters (K) is a critical step in the K-Means algorithm. There are several methods to choose from, including:
- The Elbow Method: Plotting the sum of squared errors (SSE) against the number of clusters to identify the point of diminishing returns.
- The Silhouette Method: Evaluating the separation and cohesion of the clusters to determine the optimal K.
- The Gap Statistic Method: Comparing the log-likelihood of the data under different clustering models to select the optimal K.

Step 3: Implement K-Means in Excel
Once you've prepared your data and chosen the optimal K, you can implement the K-Means algorithm in Excel using the following methods:
- Using the K-Means Add-in: This add-in provides a user-friendly interface for performing K-Means clustering.
- Using VBA Macros: Writing custom VBA code to implement the K-Means algorithm.
- Using Formulas: Using a combination of Excel formulas to perform the clustering.

Step 4: Interpret and Visualize the Results
After running the K-Means algorithm, it's essential to interpret and visualize the results to gain insights into the clustering structure. This involves:
- Examining the cluster assignments and characteristics
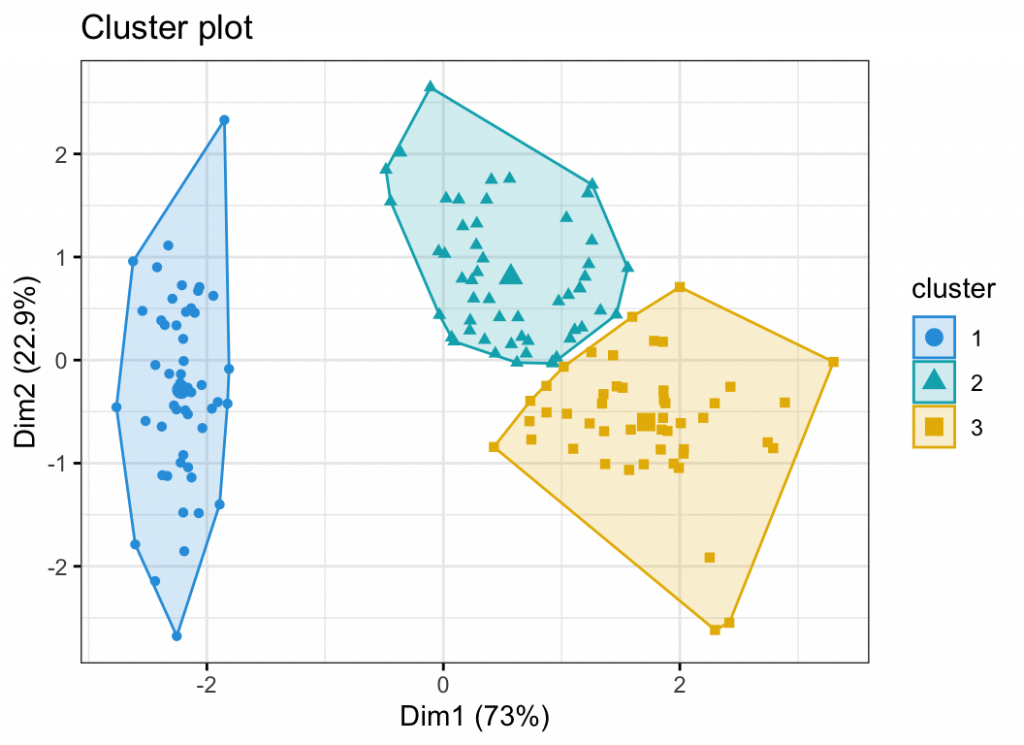
- Visualizing the clusters using scatter plots, heatmaps, or other visualization tools
- Evaluating the quality of the clustering using metrics such as the silhouette coefficient or the Calinski-Harabasz index

Gallery of K-Means Cluster Analysis



Frequently Asked Questions
What is the difference between K-Means and Hierarchical Clustering?
+K-Means is a partition-based clustering algorithm, whereas Hierarchical Clustering is a hierarchical-based algorithm. K-Means partitions the data into K clusters, whereas Hierarchical Clustering builds a hierarchy of clusters.
How do I choose the optimal number of clusters (K) in K-Means?
+There are several methods to choose from, including the Elbow Method, the Silhouette Method, and the Gap Statistic Method. The optimal K is the one that results in the best clustering structure, as evaluated by metrics such as the silhouette coefficient or the Calinski-Harabasz index.
Can I use K-Means for categorical data?
+No, K-Means is typically used for numerical data. For categorical data, other clustering algorithms such as K-Modes or Hierarchical Clustering may be more suitable.
By following the steps outlined in this article, you'll be well on your way to mastering Excel K-Means cluster analysis. Remember to prepare your data, choose the optimal number of clusters, implement the algorithm, and interpret and visualize the results. With practice and patience, you'll become proficient in using K-Means to uncover hidden patterns and insights in your data.